
동적 메모리 할당기를 만드는 이유?
- 동적 메모리 할당을 하지 않는다면, 배열을 정해진 최대 배열 크기를 갖는 정적 배열로 정의할 것이다. 작은 프로그램에서는 이 방법이 크게 문제가 되지 않을 수 있지만 코드 길이가 길어질수록 사용자가 많은 규모의 소프트웨어라면 정적배열 선언은 관리가 어려워집니다.
- 이 어려움을 해결하기위해 런타임시 메모리에 데이터를 동적으로 할당해야 합니다.
할당기에는 아래와 같이 크게 2종류가 있습니다.
- 명시적 할당기(Explicit Allocator) : 명시적 할당기는 프로그래머가 직접 메모리를 할당하고 해제하는 방식을 의미합니다. 프로그래머는 메모리를 동적으로 할당하기 위해 할당하는 함수(malloc) 해제하는 함수(free)를 호출해야 합니다.
- 묵시적 할당기(Implicit Allocator) : 묵시적 할당기는 프로그래머가 직접 메모리를 할당하고 해제하는 대신, 언어나 런타임 시스템이 자동으로 메모리를 할당하고 해제하는 방식을 말합니다. 일반적으로 가비지 컬렉터가 묵시적 할당기의 일종입니다. 가비지 컬렉터는 더 이상 사용되지 않는 메모리를 자동으로 감지하고 해제하여 프로그래머가 메모리 관리에 대한 부담을 줄여줍니다.
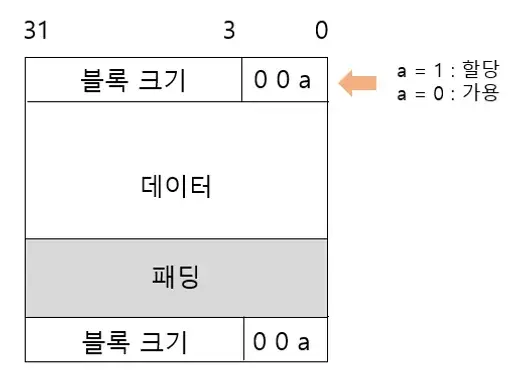
대부분의 할당기는 정보를 블록 내에 저장하는데 블록 한개에는 위와 같은 정보들이 들어간다.
- 헤더 : 블록 크기와 블록 할당 여부를 담고있습니다.
- 데이터 : 담아야 할 데이터(payload)
- 패딩 : 외부 단편화를 극복하기 위한 전략의 일부분으로 사용할 수도 있고, 정렬 요구사항을 만족하기 위해 필요합니다.
보통 하나의 블록은 4바이트나 8바이트로 구성하는데, 그걸 부르는 단위를 word라고 부른다. 따라서 1워드는 4바이트이고, 더블 워드가 될 경우 8바이트가 된다. 블록 크기는 대개 4의 배수 혹은 8의 배수로 구분된다.
1️⃣ 첫 층은 헤더로서 블록 크기와 가용 여부를 나타냅니다. 가용 여부는 마지막 비트의 0과 1로 가용을 구분합니다. 또한 블록 크기는 16진수 비트로 이루어 지기 때문에 가용 여부도 16진수 비트로 구성해야합니다.
2️⃣ 두번째 층은 데이터입니다. 할당된 블록의 경우 특정한 자료가 담깁니다.
3️⃣ 세번째 층은 패딩입니다. 패딩은 블록의 크기를 일괄적으로 정렬해야 하기때문에 들어갑니다.
- 예를 들어 크기가 2byte인 데이터를 넣어야 하면, 컴퓨터는 16byte 블록을 할당할 것입니다. 왜냐하면 블록에 header와 footer는 무조건 들어가야 하는데, 이들은 각각 4바이트씩이기때문입니다.
- 2+4+4 = 10byte로 생성 요건을 충족했지만, 방금 말했듯이 규격화해야하고 8의 배수 등으로 무조건 정렬 조건을 만족해야 하기 때문이다. 이미 들어가야 하는 자료가 8byte를 넘으니 6 byte를 더해서 16byte 블록을 할당합니다. 이때 패딩을 사용해 6byte가 들어가게 된다.
4️⃣ 마지막 층은 블록의 푸터입니다. 푸터는 헤더와 동일한 기능을 수행합니다. 이전 블록은 항상 현재 블록의 시작 부분에서 1word 앞에 위치하기 때문에 푸터를 넣음으로써 이전 블록과 다음 블록의 상태를 쉽게 파악할 수 있습니다.
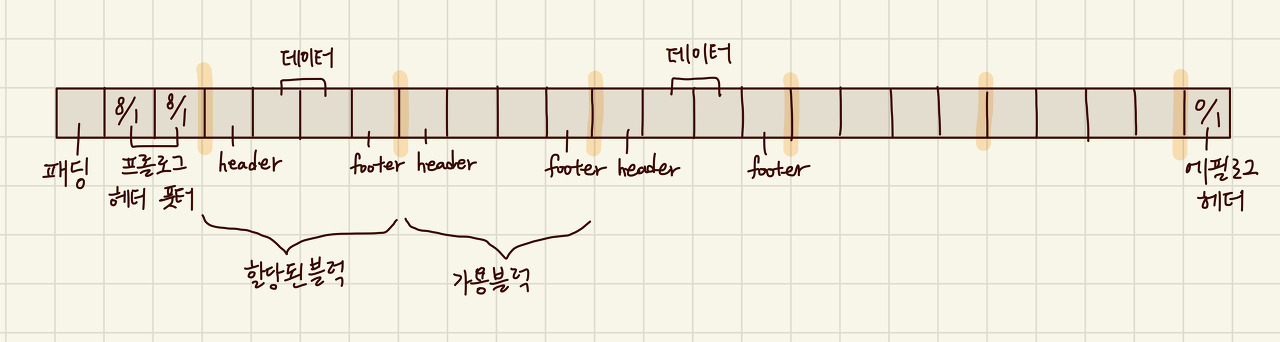
- 프롤로그 헤더 : 프롤로그 헤더는 할당된 메모리 블록 앞에 위치하는 고정 크기의 데이터 구조입니다. 일반적으로 메모리 블록의 시작 부분에 삽입됩니다. 프롤로그 헤더는 메모리 블록의 크기, 할당 여부, 이전 및 다음 메모리 블록과의 연결 등의 정보를 포함합니다. 할당기는 이 정보를 사용하여 메모리 블록을 찾고 관리합니다.
- 프롤로그 푸터 : 프롤로그 푸터는 할당된 메모리 블록의 프롤로그 헤더와 맞물려 사용되는 데이터 구조입니다. 프롤로그 푸터는 프롤로그 헤더의 일부 정보를 중복 저장하는 역할을 합니다. 이는 할당기가 메모리 블록의 일관성을 확인하고 유효성을 검사하는 데 사용됩니다.
- 에필로그 헤더 : 에필로그 헤더는 할당된 메모리 블록의 끝 부분에 위치하는 고정 크기의 데이터 구조입니다. 일반적으로 메모리 블록의 끝에서 일정한 크기를 차지합니다. 에필로그 헤더는 메모리 블록의 할당 여부, 이전 메모리 블록과의 연결 등의 정보를 저장합니다. 할당기는 이 정보를 사용하여 메모리 블록을 관리하고 해제된 블록을 탐지합니다.
프롤로그 헤더, 프롤로그 푸터, 에필로그 헤더는 할당된 메모리 블록을 식별하고 추적하기 위한 중요한 역할을 합니다. 이들은 메모리 할당 및 해제 작업의 정확성과 일관성을 유지하는 데 도움을 주는데 사용됩니다.
Segregated 기법
- Segregated 기법은 메모리 블록을 동적으로 할당할 때, 미리 정의된 크기 범위에 따라 분류합니다.
- 예를 들어, 작은 크기의 메모리 블록은 작은 크기 클래스에 할당되고, 큰 크기의 메모리 블록은 큰 크기 클래스에 할당됩니다. 이렇게 분류된 메모리 블록은 각각의 클래스에 맞는 연결 리스트에 저장됩니다.
Segregated 단계
- 초기화 : 할당 및 해제에 사용할 메모리 영역을 초기화하고, 각 클래스의 연결 리스트를 초기화합니다.
- 할당 : 메모리 블록을 요청받으면 요청된 크기에 가장 가까운 클래스를 선택하고, 해당 클래스의 연결 리스트에서 사용 가능한 블록을 찾습니다. 사용 가능한 블록이 없으면 더 큰 클래스로 이동하여 다시 시도합니다. 사용 가능한 블록을 찾게 되면 해당 블록을 할당하고, 필요한 경우 블록을 분할하여 사용하지 않은 나머지 부분을 다른 클래스에 삽입합니다.
- 해제 : 할당된 메모리 블록을 해제하면, 해당 블록을 클래스에 맞는 연결 리스트에 삽입합니다. 이때, 연결 리스트에서 연속된 블록이 합쳐질 수 있는 경우 합침(콜라싱)을 수행하여 단편화를 최소화합니다.
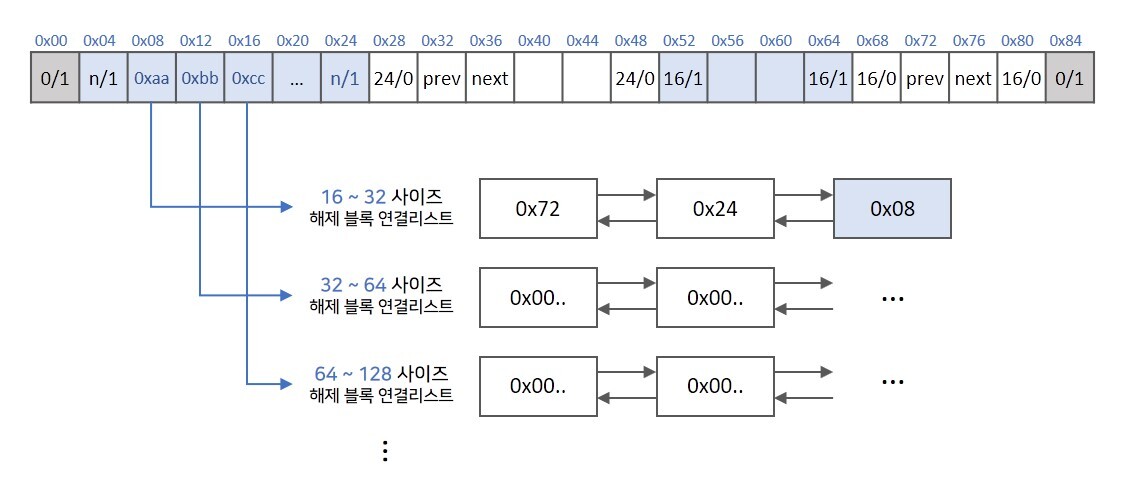
Segregated 기법은 메모리 블록의 크기에 따라 분류하여 메모리를 효율적으로 관리할 수 있습니다. 작은 크기의 할당 요청이 많은 경우 작은 클래스에서 빠르게 사용 가능한 블록을 찾을 수 있으며, 큰 크기의 할당 요청이 있을 때는 더 큰 클래스로 이동하여 대응할 수 있습니다.
할당이 해제된 블록을 유사한 사이즈의 블록들이 모여있는 리스트에서 찾기 때문에 빠른 속도로 찾을 수 있어 가장 성능이 좋습니다. 해당 리스트에서 사이즈에 맞는 블록을 찾지 못하면 다음 크기의 리스트로 넘어가서 할당할 블록을 찾게 됩니다.
'C언어' 카테고리의 다른 글
| [C] 동적 메모리 할당(malloc, calloc, realloc) (0) | 2023.05.18 |
|---|---|
| [C] Linux/gcc 사용법 , vi 에디터 명령어 (0) | 2023.05.05 |