
💡Pintos_8팀 WIL
일별 진행 목록
- 23.05.26(금)
- github team repository 생성
- git clone 후
- AWS환경에서의 Ubuntu18.04 환경설정
- 23.05.27(토)
- Alarm Clock🕰️ 구현 시작
- 목표 : 호출한 프로세스를 정해진 시간 이후에 다시 시작하는 커널 내부 함수 구현
- Busy waiting -> sleep, awake
- 쓰레드 디스크립터 필드 추가(wakeup_tick)
- 전역 변수 추가(next_tick_to_awake)
- thread_init() 함수 수정
- timer_sleep() 함수 수정
- 23.05.29(월)
- thread_sleep() 함수 구현
- timer_interrupt() 함수 수정
- thread_awake() 함수 구현
- update_next_tick_to_awake() 함수 추가
- get_next_tick_to_awake() 함수 추가
- pintos -- -q run alarm-multiple로 결과 확인
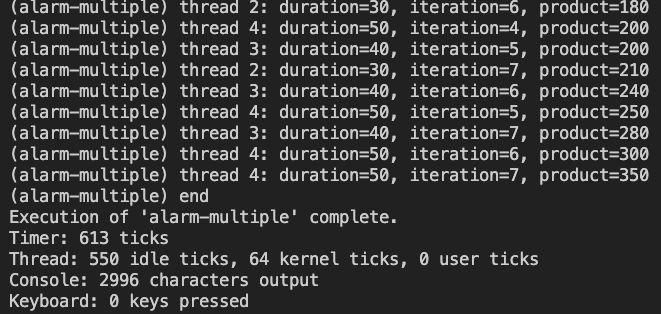
- 23.05.30(화)
- Priority Scheduling🗓️ 구현 시작
- 목표 : 현재 라운드 로빈으로 스케줄링이 되어있는것을 우선순위를 고려하여 스케줄링 수정하기.
- Priority Scheduling 개념 공부
- test_max_priority() 함수 추가
- cmp_priority() 함수 추가
- thread_create() 함수 수정
- thread_set_priority() 함수 수정
- ready_list를 우선순위로 정렬 하기 위해 thread_unblock(), thread_yield() 수정 - - Priorty Scheduling-Synchronization📖 구현 시작
- sema_down() 함수 수정
- sema_up() 함수 수정
- cond_wait() 함수 수정
- cond_signal() 함수 수정
- cmp_sem_priority() 함수 추가
- make check로 결과 확인
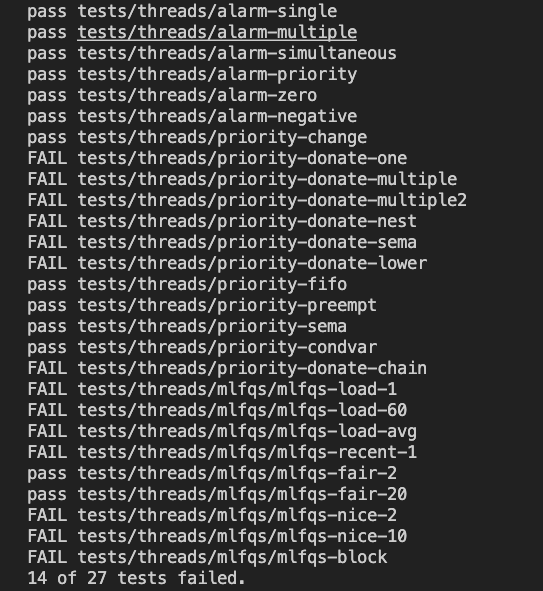
- 23.05.30(수)
- Priority Inversion (Priority donation, Multiple donation, Nested donation)🎁 구현 시작
- struct thread 필드 추가
- init_thread() 함수 수정
- lock_acquire() 함수 수정
- lock_release() 함수 수정
- thread_set_priority() 함수 수정
- donate_priority() 함수 추가
- remove_with_lock() 함수 추가
- refresh_priority() 함수 추가
- thread_set_priority() 함수 수정
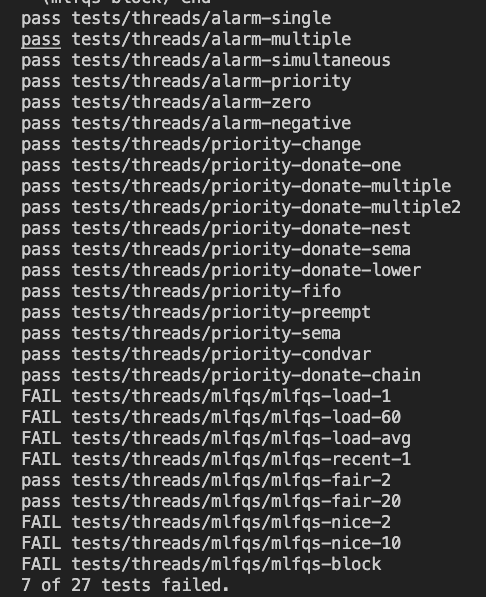
학습내용
1. Thread
- 프로세스를 구성하는 실행의 흐름 단위
- 하나의 프로세스는 여러 개의 스레드를 가질 수 있음
- 최근 많은 운영체제는 CPU에 처리할 작업 전달 시 프로세스가 아닌 스레드 단위로 전달
- 프로세스 자원을 공유한 채 실행에 필요한 최소한의 정보만으로 실행
ⅰ) 단일 스레드 프로세스
- 실행 흐름이 하나인 프로세스
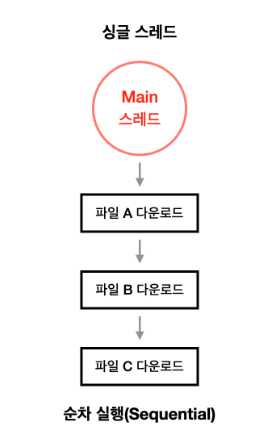
ⅱ) 멀티 스레드 프로세스
- 실행 흐름이 여러 개인 프로세스→프로세스를 이루는 여러 명령어 동시 실행 가능
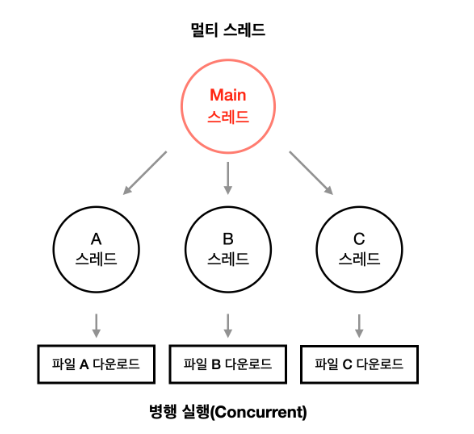
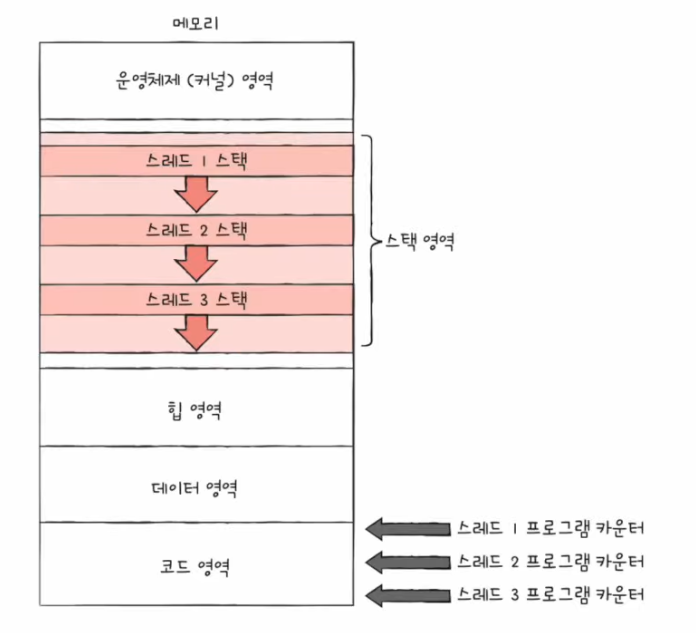
ⅲ) 스레드 구성요소
- 스레드 ID, 프로그램 카운터를 비롯한 레지스터 값, 스택 등 실행에 필요한 최소한의 정보
- 코드영역에는 실행해야하는 명령어가 들어감
- 프로세스의 스레드들은 실행에 필요한 최소한의 정보만을 유지한 채 프로세스 자원을 공유하며 실행
- 스레드마다 코드/데이터/힙영역이 있는 게 아닌 프로세스의 자원을 공유한다는 것이 핵심
Q. 동일한 작업을 수행하는 단일 스레드 프로세스 여러 개를 실행하는 것과 하나의 프로세스를 여러 스레드로 실행하는 것이 무엇이 다를까?
A. 프로세스끼리는 자원을 공유하지 않지만, 스레드끼리는 같은 프로세스 내의 자원 공유.
프로세스를 fork하여 같은 작업을 하는 동일한 프로세스 실행 시 코드, 데이터, 힙영역 등 모든 자원 복제 후 메모리 적재→메모리 동일 내용 중복 존재, 스레드는 프로세스 내 자원공유로 메모리 효율적 사용 가능→협력과 통신 유리
Q. 프로세스의 자원을 공유하는 쓰레드의 특성에 단점은 없을까?
A. 멀티스레드 환경에서는 하나의 스레드에 문제가 생기면 프로세스 전체에 문제가 생길 가능성 존재.
동기화문제→해결책 : Lock, Semaphores 등
2.Scheduling
- 모든 프로세스는 운영체제로부터 자원 할당 받음
- 프로세스마다 필요로 하는 자원은 각기 다르나, 모든 프로세스가 공통으로 사용하는 자원이 있다면 그건 CPU
- 따라서 운영체제는 CPU를 할당할 프로세스를 선택해야 함
→운영체제는 스케줄링 큐로 구현하고 관리(★스케줄링 큐에서는 반드시 FIFO일 필요는 없음)
ⅰ) 비선점형 스케줄링(non-preemptive scheduling)
- 하나의 프로세스가 자원을 사용하고 있다면 그 프로세스가 종료되거나 스스로 대기 상태에 접어들기 전까진 다른 프로세스가 끼어들 수 없는 스케줄링 방식
- 자원 사용 독점 가능, 골고루 자원 이용 어려움
- 선점형에 비해 문맥교환에서 발생하는 오버헤드가 적음
ⅱ) 선점형 스케줄링(preemptive scheduling)
- 프로세스가 CPU를 사용하고 있더라도 운영체제가 프로세스로부터 자원을 빼앗아 다른 프로세스에 할당할 수 있는 스케줄링 방식
- 하나의 프로세스가 자원 사용 독점 불가, 자원 배분 가능
- 문맥교환 과정에서 오버헤드 발생 가능성
ⅲ) 스케줄링 알고리즘의 종류
- 라운드 로빈 스케줄링(round robin scheduling)
- 삽입된 순서대로 CPU를 이용, 정해진 시간 만큼만.
- 시간 내에 완료되지 않았다면 다시 큐의 맨 뒤에 삽입 → 문맥교환 발생
- 선입 선처리 스케줄링 + **time slice**
- 타임 슬라이스 : 각 프로세스가 CPU를 사용할 수 있는 정해진 시간
- 타임 슬라이스 크기 매우 중요
- 지나치게 크면 호위효과(장시간 대기)
- 적으면 문맥 교환 발생 비용 커짐
- 우선순위 스케줄링(priority scheduling)
- 우선순위 부여, 가장 높은 우선순위를 가진 것부터 실행
- 우선순위가 같을 경우 선입 선처리
- 근본적인 문제점 : 기아(starvation)현상
- 우선순위 낮은 프로세스 실행 연기
- 해결책 : 에이징(aging)기법
- 오랫동안 대기한 프로세스 우선순위를 점차 높이는 방식
3. Synchronization
- 동시다발적으로 실행되는 수많은 프로세스는 서로 협력하기도 하고, 자원을 두고 경쟁하기도 함
- 프로세스(스레드 포함) 동시 실행 시 실행 순서와 자원의 일관성 보장을 위해 반드시 거쳐야 함
- 실행 순서 제어를 위한 동기화 : 올바른 순서대로 실행하는 것
- 상호 배제를 위한 동기화 : 동시에 접근해서는 안 되는 자원에 하나만 접근하게 하기
- 공유자원 : 여러 스레드에 의해 공유되어 사용되는 자원
- 임계구역 : 동시에 실행하면 문제가 발생하는 자원에 접근하는 코드 영역
- 같은 공유 데이터를 여러 스레드에서 동시 접근 시 시간차이로 인한 잘못된 결과로 이어질 수 있기 때문에 하나의 스레드가 임계구역에 들어가 있다면 다른 스레드들은 임계구역에 접근하는 것을 제한해야 함
- 3가지 원칙
- 상호배제 : 한 스레드가 임계 구역에 진입했다면 다른 스레드는 임계 구역에 들어올 수 없다.
- 진행 : 임계 구역에 어떤 스레드도 진입하지 않았다면 임계 구역에 진입하고자 하는 스레드는
들어갈 수 있어야 한다. - 유한 대기 : 한 스레드가 임계 구역에 진입하고 싶다면 그 스레드는 언젠가는 임계 구역에 들어올
수 있어야 한다. (무한정 대기해서는 안된다.)
ⅰ) 뮤텍스 락 (Mutex lock)
- 상호 배제를 위한 동기화 도구
- 하나의 공유 자원에 접근하는 프로세스를 상정한 방식
- 자물쇠 역할 : 프로세스(스레드)들이 공유하는 전역 변수 lock
- 임계 구역을 잠그는 역할 : acquire함수
- 임계 구역 진입 전 호출 함수
- 임계 구역이 잠겨 있다면 열릴 때까지(lock이 false가 될 때까지) 반복적 확인
- 임계 구역이 열려 있다면 임계 구역을 잠그는 (lock을 true로 바꾸는) 함수
- 임계 구역의 잠금을 해제하는 역할 : release 함수
- 임계 구역에서 작업 끝나고 호출하는 함수
- 현재 잠긴 임계 구역을 열어주는(lock을 false로 바꾸는) 함수
acquire() {
while (lock == true) // 만약 임계 구역이 잠겨 있다면
; // 임계 구역이 잠겨 있는지를 반복적으로 확인
lock = true; // 임계 구역 작업이 끝났으니 작업 해제
}
release() {
lock = false; // 임계 구역 작업이 끝났으니 작업 해제
}
ⅱ) 세마포 (semaphore)
- 뮤텍스 락과 비슷, 공유 자원이 여러 개 있는 상황에서도 적용 가능한 동기화 도구
- nonnegative integer (전역변수S) : 임계 구역에 진입할 수 있는 스레드의 개수 (사용 가능한 공유 자원의 개수)
- operator
- "Down" (or "P")
- 스레드가 임계 구역으로 들어와서 공유자원 사용 요청 시 실행
- 현재 사용 가능한 공유 자원의 개수가 1개 이상이면 1 줄이고 임계 구역 실행 (공유 자원 사용)
- 현재 사용 가능한 공유자원의 개수가 0이하면 양수가 될 때까지 대기
- wait 함수 : 임계 구역에 들어가도 좋은지, 기다려야 할지 알려주는 함수
wait ( ) {
while ( S <= 0 ) // 만일 임계 구역에 진입할 수 있는 프로세스가 0 이하라면
; // 사용할 수 있는 자원이 있는지 반복적으로 확인하고
S--; // 임계 구역에 진입할 수 있는 프로세스 개수가 하나 이상이면
// S를 1감소 시키고 임계 구역 진입- "Up" (or "V")
- 스레드가 임계 구역 실행 모두 마치고 공유자원 반납 시 실행
- 사용 가능한 공유 자원의 개수 +1
- signal 함수 : 임계 구역 앞에서 기다리는 스레드에 '가도 좋다'고 신호를 주는 함수
signal ( ) {
S++; // 임계 구역에서 작업을 마친 뒤 S를 1 증가시킨다
ⅲ) 모니터 (monitor)
- 공유 자원과 공유 자원에 접근하기 위한 인터페이스 (통로)를 묶어 관리
- 프로세스는 반드시 인터페이스를 통해서만 공유 자원에 접근
void put (char ch) {
lock_acquire (&lock);
while (n == BUF_SIZE)
cond_wait (¬_full, &lock);
buf [ head++ % BUF_SIZE ] = ch;
n++;
cond_signal (¬_empty, &lock);
lock_release (&lock);
}
char get (void) {
char ch;
lock\_acquire (&lock);
while (n == 0)
cond\_wait (¬\_empty, &lock);
ch = buf \[ tail++ % BUF\_SIZE \];
n--;
cond\_signal (¬\_full , &lock);
lock\_release (&lock);
}- 이 예제에서 producer 스레드들은 put 함수를 통해 글자 입력
- consumer 스레드들은 get 함수를 통해 글자 읽음
- 버퍼 크기 한정적
- BUF_SIZE가 가득 찬 경우 put을 block
- BUF_SIZE가 빈 경우 get을 block
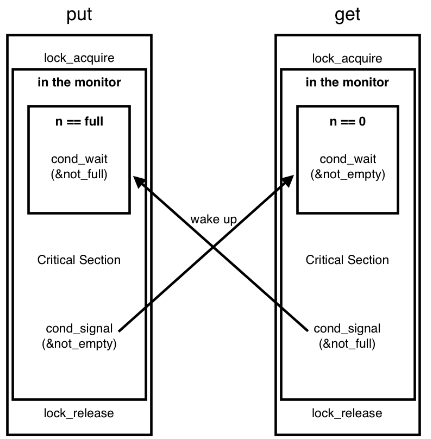
▶ 처음 빈 버퍼 → get은 cond_wait (¬_empty) 에 의해 not_empty 가 true가 될 때까지 대기 상태
▶ put 함수로 버퍼에 쓰고 cond_signal (¬_empty) 호출 → ¬_empty 조건을 true로 만듦
▶ get 함수가 대기상태에서 진행상태로 변경 → 버퍼에 써진 내용 읽음
▶ put 함수 반복 → 가득 찬 버퍼 → put 함수는 cond_wait (¬_full) 로 put 함수 대기상태로 만듦
▶ get 함수가 글자를 읽어 버퍼를 비움 → cond_signal(¬_full) 통해 not_full 조건을 true로 만들고 실행
4. Alarm clock🕰️
ⅰ) Busy waiting
- 어떤 조건을 만족하지 못할 경우에, 그 조건을 만족할 때 까지 다른 작업을 수행하지 않고 기다리는 경우를 의미
- 현재 Alarm clock이 Busy waiting으로 구현되어 있어 idle ticks가 생기지 못함
ⅱ) Sleep and Awake
- Sleep (대기 상태): sleep은 스레드가 특정 시간 동안 대기 상태로 들어가는 것을 의미
- Awake (활성 상태): awake는 sleep 상태에서 깨어나 ready list로 이동. 특정 조건이 충족되거나 지정된 시간이 경과하면 스레드는 ready list로 전환되고 이후 스케줄러에 의해 CPU를 할당받아 실행
- Sleep and Awake를 통해 idle ticks가 생김
5. Priority donation
ⅰ) Multiple donation
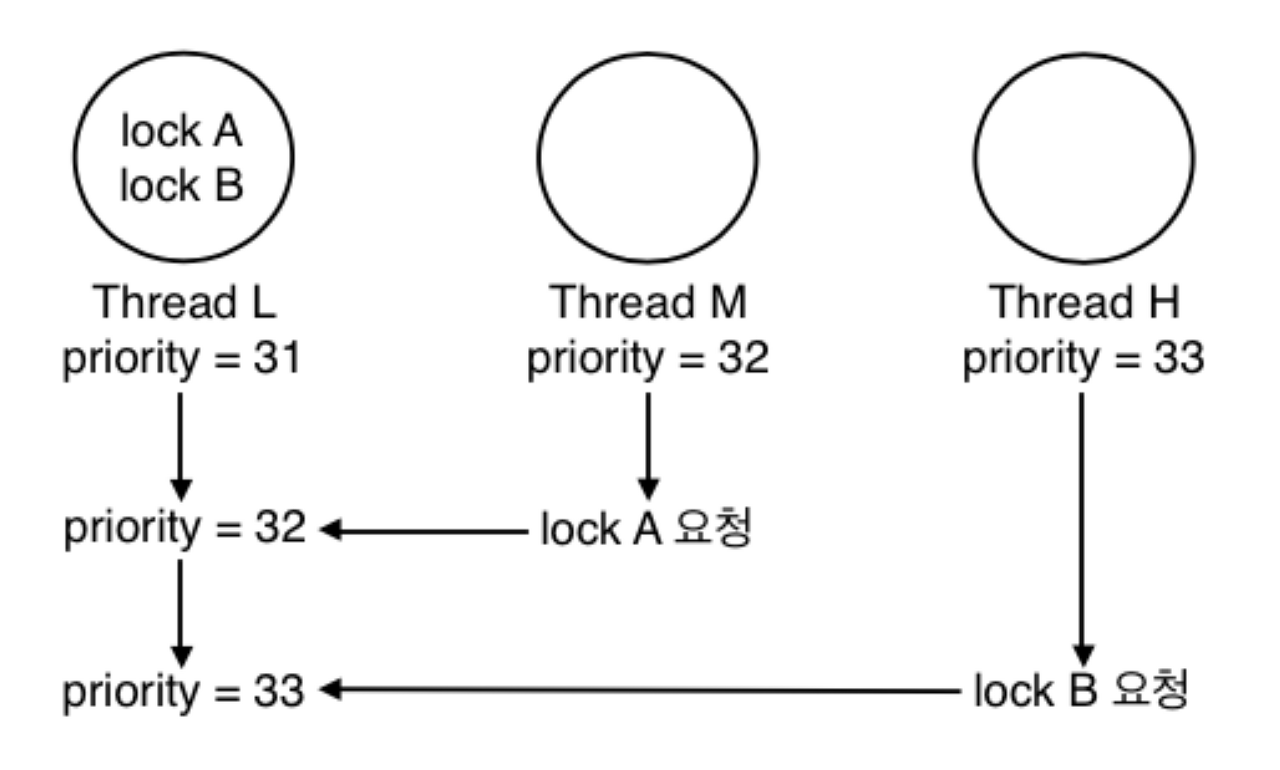
- "Multiple donation"은 donation이 여러번 발생하는 상황을 뜻함
- 위의 사진에서 Thread L이 Thread M과 Thread H에게 donation을 받아 여러번의 donation이 발생
- Thread L은 우선순위가 높은것 부터 실행 후 다음 우선순위로 넘어감
ⅱ) Nested donation
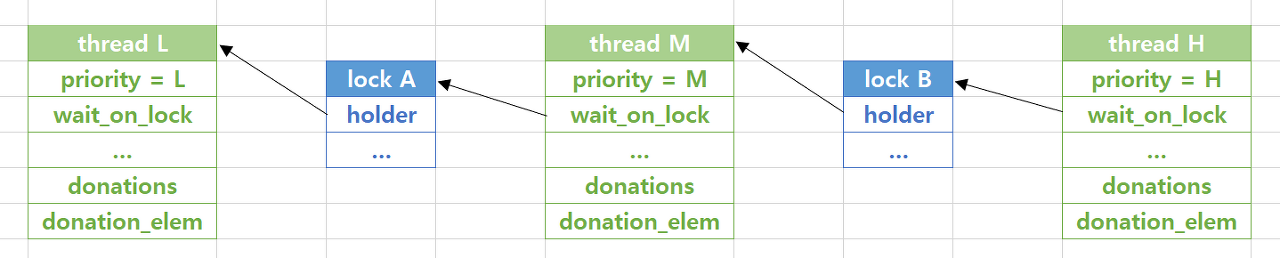
- 위의 사진에서 Thread H가 lock B(Thread M 점유상태)를 얻기 위해 대기, 이때 Thread M은 lock A(Thread L 점유상태)를 얻기위해 대기
- Thread H의 우선순위는 Thread L,M에게 모두 donation 되어야함
회고
Trouble Shooting 🎯
ⅰ) cmp_sem_priority()
bool
cmp_sem_priority (const struct list_elem *a, const struct list_elem *b, void *aux UNUSED){
struct semaphore_elem* sema_thread_a = list_entry(a,struct semaphore_elem,elem);
struct semaphore_elem* sema_thread_b = list_entry(b,struct semaphore_elem,elem);
struct list_elem* waiting_list_a = &(sema_thread_a->semaphore.waiters);
struct list_elem* waiting_list_b = &(sema_thread_b->semaphore.waiters);
struct thread* thread_a = list_entry(list_begin(waiting_list_a),struct thread,elem);
struct thread* thread_b = list_entry(list_begin(waiting_list_b),struct thread,elem);
// /* 첫 번째 인자의 우선순위가 두 번째 인자의 우선순위보다 크면 1반환 아니면 0반환*/
// struct thread* thread_a = list_entry(a,struct thread,elem);
// struct thread* thread_b = list_entry(b,struct thread,elem);
return thread_a->priority > thread_b->priority;
}- 원인 : 기존 cmp_priority()함수와 같이 인자로 넣어 준 스레드들 끼리의 우선순위 비교와 같다고 생각해서 구현
- 해결 : cond_wait()함수에서 우선순위로 삽입할 때 semaphore의 waiting list에 삽입하는데, waiting list를 참조해서 우선순위를 비교해야하므로semaphore_elem구조체에서 semaphore의 waiting list의 스레드 우선순위를 정해서 구현. 따라서 해당 세마포어의 우선순위를 그 안의 스레드의 우선순위로 정할 수 있음
ⅱ) thread_set_priority()
void
thread_set_priority (int new_priority) {
thread_current ()->init_priority = new_priority;
refresh_priority();
test_max_priority();
}- 원인 : thread_current()->priority = new_priority; 인자로 받은 new_priority를 현재 스레드의 우선순위로 지정해서 몇몇의 테스트 실패
- 해결 : thread_current()->init_priority = new_priority; 로 수정해서 해결. 새로 받은 우선순위를 init_priority에 저장하지 않는다면 스레드의 우선순위를 재설정하는 refresh_priority()함수부분에서 init_priority를 설정해주는데 이 부분에서 오차 발생. 따라서 우선순위를 바꿔줄 때에는 init_priority를 바꿔줘야 함
느낀점
▶ 프로젝트를 시작할 때, 개념부터 정립 해야 할지 코드를 바로 구현 해야 할지 고민 되어서 시범적으로 이지현 팀원은 파트별로 개념 공부 후 코드 구현, 박윤찬 팀원은 코드 구현 하면서 개념을 공부하는 방식으로 진행
▶ 각 과정의 장단점과 코드를 비교 한 결과 이후부터는 구현해야 할 부분 단위로 개념을 쪼개서 순차적으로 진행하기로 결정.
- 한양대 pintos 자료를 보면서 주어진 내용대로 코드를 구현해보고 test에 맞는 결과가 나오면 다음 기능을 구현하는 식으로 진행해보니 개념이 좀 복잡하거나 전반적인 코드의 흐름을 필요로 하는 구현 부분에서 어려움을 느낌
▶ 다음 과제부터는 자료를 참고하여 구현했다 하더라도 전반적으로 코드와 개념을 매칭하면서 분석하는 과정을 진행하기로 함
- 이번 1주차는 WIL말고는 팀의 진행상황 및 의견 공유부분을 기록으로 남기는 것이 적었음.
▶ 2주차부터는 github의 discussion 및 issue 기능을 활용하여 소통을 기록할 수 있도록 추진
GITHUB
https://github.com/Blue-club/pintos_8
GitHub - Blue-club/pintos_8
Contribute to Blue-club/pintos_8 development by creating an account on GitHub.
github.com
'운영체제' 카테고리의 다른 글
| [Pintos-Kaist] Project2 - Argument Passing (1) | 2023.06.05 |
|---|---|
| [운영체제] 인터럽트 & 시스템 콜(Interrupt, System Call) (0) | 2023.06.02 |
| [운영체제] 스핀락(Spinlock),뮤텍스(Mutex),세마포어(Semaphore) (0) | 2023.05.29 |
| [운영체제] 동시성(Concurrency)과 병렬성(Parallelism) (0) | 2023.05.27 |
| [운영체제] 프로세스(Process)와 스레드(Thread) (0) | 2023.05.27 |