
앞서 1번 포스팅에서는 DeadLock에 대해서 알아봤습니다. 이번에는 Redis가 무엇인지 그리고 Redis Cluster, Replication, 대기열에 대해서 알아보도록 하겠습니다.
🧐 Redis
Redis(Remote Dictionary Storage, 레디스)는 모든 데이터를 메모리에 저장하고 조회하는 인메모리 데이터베이스, 메모리 기반의 key-value 구조의 데이터 관리 시스템이다.
Redis는 인메모리 데이터 스토어로서 매우 빠른 데이터 액세스와 처리를 제공하는 오픈 소스 데이터베이스 시스템입니다. 주로 캐싱, 세션 관리, 메시지 브로커 등 다양한 용도로 사용됩니다.
Redis의 다양한 특징들
1. In-Memory 데이터 저장
- 데이터를 메모리에 저장하여 매우 빠른 읽기 및 쓰기 작업을 가능하게 합니다. 따라서 데이터 액세스 속도가 매우 빠르며 주로 캐싱용도로 사용됩니다.
2. 다양항 데이터 타입 지원
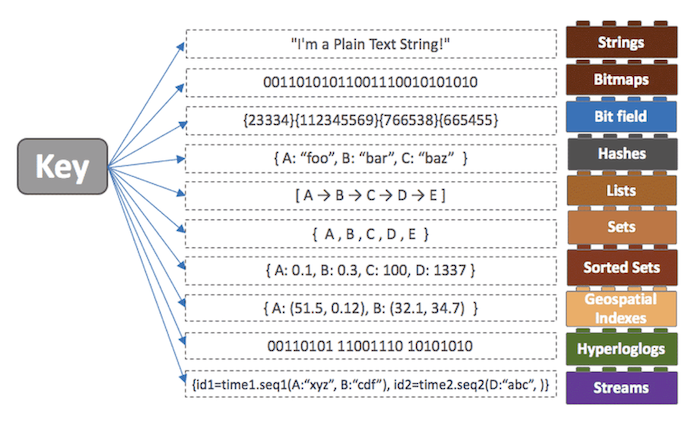
- 문자열, 해시, 리스트, 셋, 정렬된 집합 등 다양한 데이터 구조를 활용하여 유연한 데이터 모델링이 가능합니다.
3. Pub-Sub 메시징 시스템
- 발행-구독(Pub-Sub) 모델을 통해 메시지를 발행하고 해당 메시지를 구독하는 기능을 제공합니다.
4. 분산 캐싱 지원
- 여러 대의 서버에서 레디스 클러스터를 구성하여 데이터의 캐싱을 분산하여 처리할 수 있습니다.
5. 트랜잭션 지원
- 레디스는 멀티 명령을 하나의 트랜잭션으로 묶어 처리할 수 있습니다. 이를 통해 여러 작업을 원자적으로 실행하거나 롤백할 수 있습니다.
6. 싱글 스레드
- Redis는 싱글 쓰레드이기 때문에, 1번에 1개의 명령어만 실행할 수 있다. (자주 비교되는 맴캐쉬드는 멀티 스레드 지원)
- Keys(저장된 모든키를 보여주는 명령어)나 flushall(모든 데이터 삭제)등의 명령어를 사용할 때, 맴캐쉬드의 경우 1ms정도 소요되지만 레디스의 경우 100만건의 데이터 기준 1초로 엄청난 속도 차이가 있다.
- 즉 하나의 요청이 병목되면 그 다음 요청들이 계속 밀리기 때문에 O(N)관련 명령어를 주의해야한다. O(N)관련 명령어로는 위에서 언급한 Keys, flushall를 포함해 FLUSHDB, Delete COlLECTIONS, Get All Collections가 있다. 큰 컬렉션의 데이터를 다 가져오는 경우 등도 주의하자.
- 또 RDB 작업(특정 간격마다 모든 데이터를 디스크에 저장)이 매우 오래걸린다. AWS 60기가 메모리 기준으로 10분이나 소요된다고 한다. Redis 장애에 원인의 대부분이 해당 기능 때문에 발생하기 때문에 사용할 때 주의해야한다.
그리고 Redis와 자주 비교되는 Memcached 의 특징을 비교해보겠습니다.
| Redis | MemCached |
| Single Thread 사용으로 한번에 1개의 명령어만 처리 가능. O(N) | Multi Thread 사용 |
| 많은 자료구조 제공. | String(key-value)만 제공 |
| 클러스터 모드 제공. | 클러스터 모드 제공 X |
| 메모리 관리는 jemalloc 알고리즘을 사용하여 malloc과 free를 통해 메모리를 할당하고 해제하는 작업을 반복하기 때문에 파편화가 발생한다. 대규모 트래픽이 발생하면 응답속도가 느려질 수 있다. | 메모리 관리를 slab이라는 것으로 직접 chunk를 관리하여 안정적이다. |
| jemalloc은 요청한 만큼만 할당하는 것이 아니고, 32, 64, 128 과 같이 미리 정해놓은 단위로 할당한다. (메모리 할당 속도 향상과 메모리 페이지 단편화 문제를 개선하기 위함) |
메모리 파편화가 거의 일어나지 않는다. 만약 메모리가 부족할 경우 가장 적게 사용한 데이터들부터 삭제하여 메모리를 마련하므로 데이터가 사라진다는 것을 조심해야 한다. |
📍 Redis 사용사례
Remote Data Store, Ranking 보드로 사용(Sorted set), 유저 인증 토큰 저장, 메세지 큐잉, 유저 API Limit 등.
Redis Replication이란?
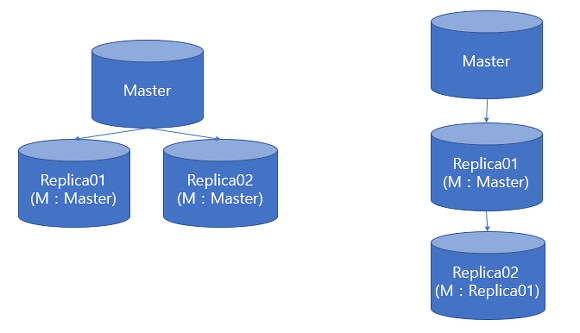
- A서버의 데이터를 B서버도 동일하게 데이터를 다루는 것.
- Redis 5.0 이상부터는 Master-Slave 보다는 Original(Primary) - Replica(Secondary)라는 용어로 사용
- 단순 Replication구조에서는 자동 failover를 할 수 없다.(수동으로 failover진행)
- 그러므로 Sentinel을 사용하여 Health-check / auto failover 사용
레디스 센티넬은 레디스 클러스터의 일부로서 마스터-슬레이브 구조를 유지하고 감시하여, 마스터 노드의 장애 발생 시 자동으로 슬레이브 노드 중 하나를 마스터로 승격시켜 서비스를 계속 운영할 수 있도록 합니다.
그럼 레디스 클러스터란 무엇인가?
레디스 클러스터는 레디스의 고가용성과 분산 처리를 위한 기능을 제공하는 데이터베이스 클러스터링 기술입니다. 레디스 클러스터는 데이터를 여러 대의 서버에 분산 저장하고 관리하여 높은 가용성과 성능을 제공하며, 데이터베이스의 확장성을 향상시킬 수 있습니다.
- Hash 기반으로 Slot 16,384로 구분
- 센티넬이나 다른 헬스체커가 필요없다. 클러스터 내에서 헬스체크를 해주고 죽으면 자동으로 Master로 승격
- 단점은 메모리 사용량이 더 많고 라이브러리 구현이 필요하다
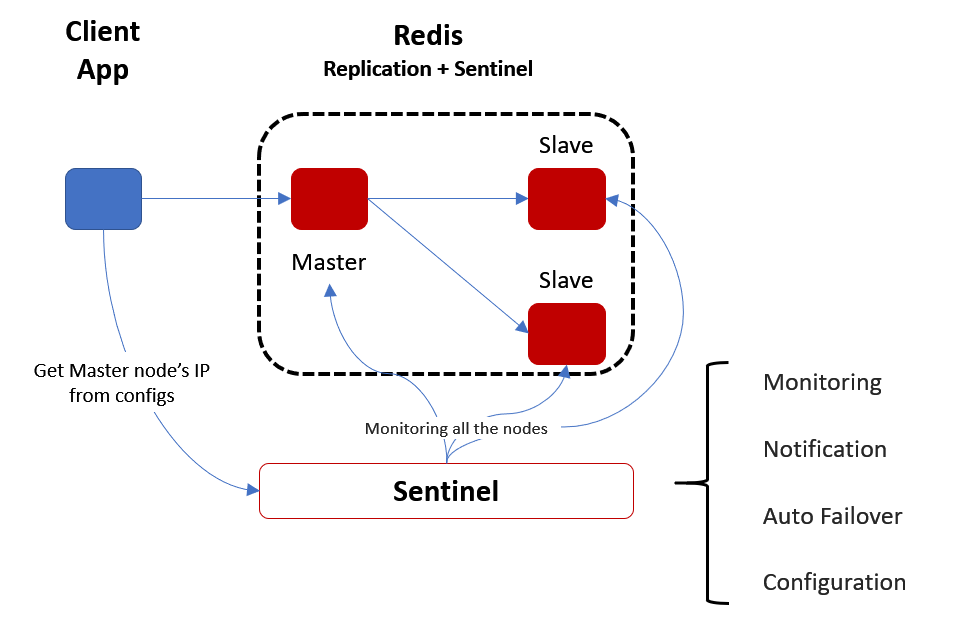
Sentinel 구성시 고려사항
- 문제없이 구성하려면 최소 3개의 Sentinel 인스턴스가 필요합니다.
- Sentinel은 홀수로 증가해야 한다.
- Quorum은 2이상(총 레디스 서버의 과반수 이상)이 되어야 한다.
- Redis-Sentinel구조는 소규모 프로젝트에 적합하고 대규모 프로젝트에서는 샤딩/Cluster 구조가 적합하다.
- Sentinel에서도 Master가 정해지는데 Sentinel들의 투표를 통해 Leader가 선출된다.
- 모든 Sentinel에서 Failover를 시도할 경우 시스템 장애가 날 수 있으므로 Master down 여부에 대한 정합성을 Leader가 최종적으로 결정한다.
마지막으로 Sentinel을 모니터링 하는 방법을 알아보자.
Redis-Sentinel 모니터링
- Redis info 명령어를 통한 정보로 확인(관리자 수동체크
- RSS: 데이터를 포함하여 실제 redis가 사용중인 메모리
- Used Memory: redis가 알고있는 사용 메모리
- Connection 수
- CPU 성능 체크: redis는 싱글스레드이므로 CPU 하나를 사용한다. 따라서 CPU단일 성능을 높이는게 좋다.
- Monitor 명령을 통해 느려지는 패턴 파악 필요
- 잘못쓰면 부하로 인해 더 큰 문제 발생 가능. 짧게 써야 한다.
- Redis-Sentinel을 통한 모니터링
- Sentinel을 통한 레디스 헬스체크 진행
- 자동 Failover 가능
이번에는 레디스에 관련된 내용들을 정리해봤습니다.
레디스 클러스터와 센티넬은 데이터베이스의 가용성, 고성능, 장애 복구 등을 개선하여 안정적이고 신뢰성 있는 서비스를 제공하는 데 도움을 준다는 것을 깨달았고, 레디스 데이터베이스 시스템을 효과적으로 운영하기 위해 적절한 기능을 선택하기 위해 사용자의 요구사항을 잘 판단하는 것이 중요하다고 생각합니다.
'운영체제' 카테고리의 다른 글
| 트랜잭션의 격리수준(Isolation level) (0) | 2023.09.01 |
|---|---|
| DeadLock과 Redis 대기열 사용하기 - (1) (0) | 2023.08.30 |
| [Pintos-Kaist] Project3 - Swap In/Out (0) | 2023.06.26 |
| [Pintos-Kaist] Project3 - Stack Growth, Memory Mapped Files (0) | 2023.06.24 |
| [Pintos-Kaist] Project3 - Anonymous Page (0) | 2023.06.19 |